Two main types of proxies are forward proxies and reverse proxies. Since they’re both proxies, it’s not immediately obvious from their names how they’re different! All proxies act as a middle man in a network topology between two parties: the client (or thing requesting a resource) and a server (the thing providing the resource).
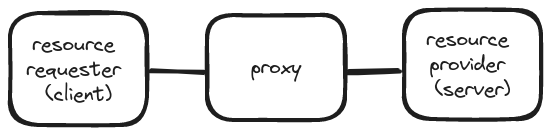
The proxy itself is technically also a server, but in most discussions / writing about proxies the “server” is referring to the server that is providing the resource (such as an HTML page) that the client is requesting. If you’re running a web service, that server would be the backend service such as a rails app.
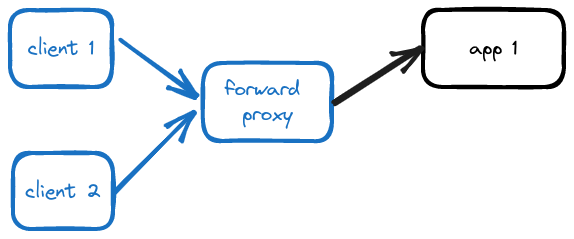
Forward Proxy
A forward proxy is a proxy that clients connect directly to and is aware of. The proxy itself is not aware of backend server identities / IP’s – it only knows how to forward and respond to requests. The client knows that its connecting to a proxy – and by client I don’t mean the actual computer user, but rather the program (perhaps a browser) that’s connecting to the wider internet. Sometimes the real user doesn’t even know that there is a proxy involved!
Here’s a couple of real scenarios involving forwarding proxies:
- A VPN service that clients can connect to hide their origin IP’s for the sake of protecting their identity (maybe for the purposes of bypassing censorship or just to remain anonymous). VPN’s are a special type of forwarding proxy that provides additional security and authentication features for the purposes of protecting the anonymity of the client requesting a resource. Since users are the ones seeking protection when signing up for VPN services, they’re also aware that the system they’re using is making use of a proxy server.
- A firewall proxy setup by school network administrators to intercept and block traffic to and from certain sites (social media sites, porn sites, etc). In this situation the computer user may be unaware that they’re being restricted – a student tries to access a restricted site and find it blocked, unaware that the client programs on their computer are configured to connect to a firewall proxy that is snooping on their requests.
Reverse Proxy
A reverse proxy is one that client programs are not aware of. Additionally, the proxy itself is aware of backend servers.
Clients have no idea that they’re connecting a reverse proxy. For example, so much of the internet services you use day to day sit behind reverse proxies – but I’m sure you have not configured your programs to connect to each one of these reverse proxy servers. Even though requests from clients are reaching the reverse proxy servers just like forwarding proxies, the clients do not actually know that they’re proxies.
On the other hand, the reverse proxy is aware of backend servers. It accepts incoming requests from clients and then forwards them to specific servers.
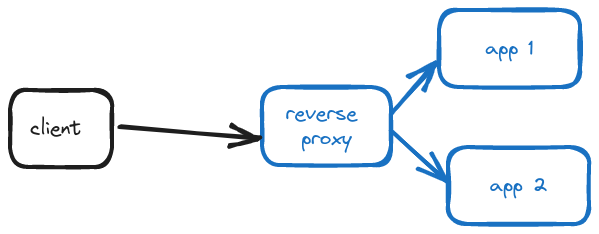
A few of the most common scenarios involving reverse proxies are:
- To improve the reliability of a service by load balancing traffic between backend servers. Nginx is a popular reverse proxy used by some of the biggest sites in the world. If you’re a developer, you can set up nginx in front of your application servers and have distributed traffic using algorithms like round robin or least time.
- To improve the security of a service by acting as the single authentication point for things like TLS handling / TLS termination and protecting the actual IP’s of your backend servers.
- To improve the performance of a service by compressing outbound traffic so that reducing response sizes to clients as well as caching static files so that requests for the same files such as images don’t need to go directly to your backend servers.
To sum it up – a forward proxy is cooperating with the clients to help the clients achieve X (bypass firewalls or in the case of firewall proxies to impose limitations). A reverse proxy is cooperating with servers / backend servers to achieve X (service reliability, security, etc).