lactate threshold workouts are very helpful for boosting performance for 10k races and beyond. the reason is that your lactate threshold limits how long your body can sustain a level of aerobic effort before needing to slow. it’s roughly an effort level around 82 – 88% of maximum heart rate sustained for an hour.
your body is always accumulating and clearing lactate. at rest or during light jogs, lactate levels remain pretty steady because you’re clearing it. but as you ramp up intensity an your anaerobic system kicks in, you stop clearing as as much as you’re producing lactate and lactate accumulates rapidly in your body. that zone is known as the threshold and where you experience muscle burn and need to slow.
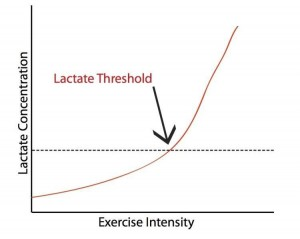
so for races that generally last longer than an hour like half marathons, that’s going to be the primary performance limiter. if you run at a pace that pushes you past your threshold, you won’t be able to sustain that pace til the end of the race. for example, let’s assume your current threshold pace is 7:00min/mile. so you can in theory sustain that for roughly an hour. now you try to run at 6:30 which is way below your threshold, you’re going to be going out too fast and will need to slow pretty quickly because you just cannot hold that pace.
by training at lactate threshold, you can create muscle adaptations that shifts the point of rapid accumulation by improving your body’s ability to clear lactate. for example, if your current LT pace is 7min/mile, that rate of effort for that pace can be sustained for about an hour (for a trained athlete who can actually stay in that zone for the duration of race). by training at or around that pace, you can extend that same previous pace for a longer distance (marathon distance maybe?) or speeding up the pace you can hold (< 7min/mile) for that same distance.
the other benefit of LT training is mental. that hour mark for sustained LT effort is sort of a cap for trained athletes that can sustain that level of effort. newer runners can’t necessarily hold that effort for an hour. it’s mentally difficult to hold that pace even if body is fully capable. so training at threshold pace also helps your mind get more comfortable with what that pace feels like.
i want to also caveat this by saying that LT workouts are definitely not something you should do without having already built up enough base endurance. if you’re new to running, doing any extended runs at a high effort level is a great way to get injured. your muscles, tendons, ligaments need to adapt to greater impact forces over time and the safe way to do that is not by jumping straight to LT training but through easy, slower running
what are some example threshold workouts?
- 20-40min continuous runs (great for mental training, race simulation … but more injury risk)
- LT intervals (break it up, short 1-2min recovery between sets so it’s less taxing overall)
- LT hills (lower impact on your joints. these can be intervals too or extended runs)
I really prefer intervals and hill work during the winter season when I’m doing most of my runs on a treadmill.
what’s the difference between let a threshold workouts and tempo workouts?
lactate threshold has a pretty specific definition. tempo is a bit more ambiguous although it’s used interchangeably sometimes with threshold. my favorite way of differentiating the two is the way jack daniels looks at it:
- threshold for a given runner is reached by a given specific pace / effort
- tempo runs may include some portions of running at threshold. for example if you do a tempo interval workout, the recovery phase will not be a threshold. or maybe it’s a long progression, with the tall end of the workout being threshold pace
- continuous long tempo runs (> 40/50min) are rarely done at threshold because then you’re practically racing… but they’re getting up there in terms of effort
so…use “threshold” when you’re referring specifically to LT threshold or workouts that are made up primarily of LT pace. use “tempo” in to include a variation of workouts that may or may not include threshold / smaller % of it is threshold.
what about norwegian double thresholds?
I am currently not fit enough to do this… but I see this everywhere. my understanding is that this got popularized due to the success of athletes like jakob ingebrigtsen. this involves doing two high volume threshold sessions in a single day, typically one in a morning and one in evening. for most non-elite athletes, doing this is probably a really, really bad idea.
one of the current top european runners andreas almgren points out two mistakes that people make about double threshold
- requires a pretty large volume of running so that you’re not sacrificing other types of workouts (vo2) as a result of going that hard in a single day and not adequately recovering
- for 5k performance, it’s still a stepping stone to more specific workouts that will help you run a faster 5k. there are other paths to build up to those workouts
either way, I’m usually pretty spent after doing one threshold session and need a full day of recovery after. will definitely get injured if I try to do a double