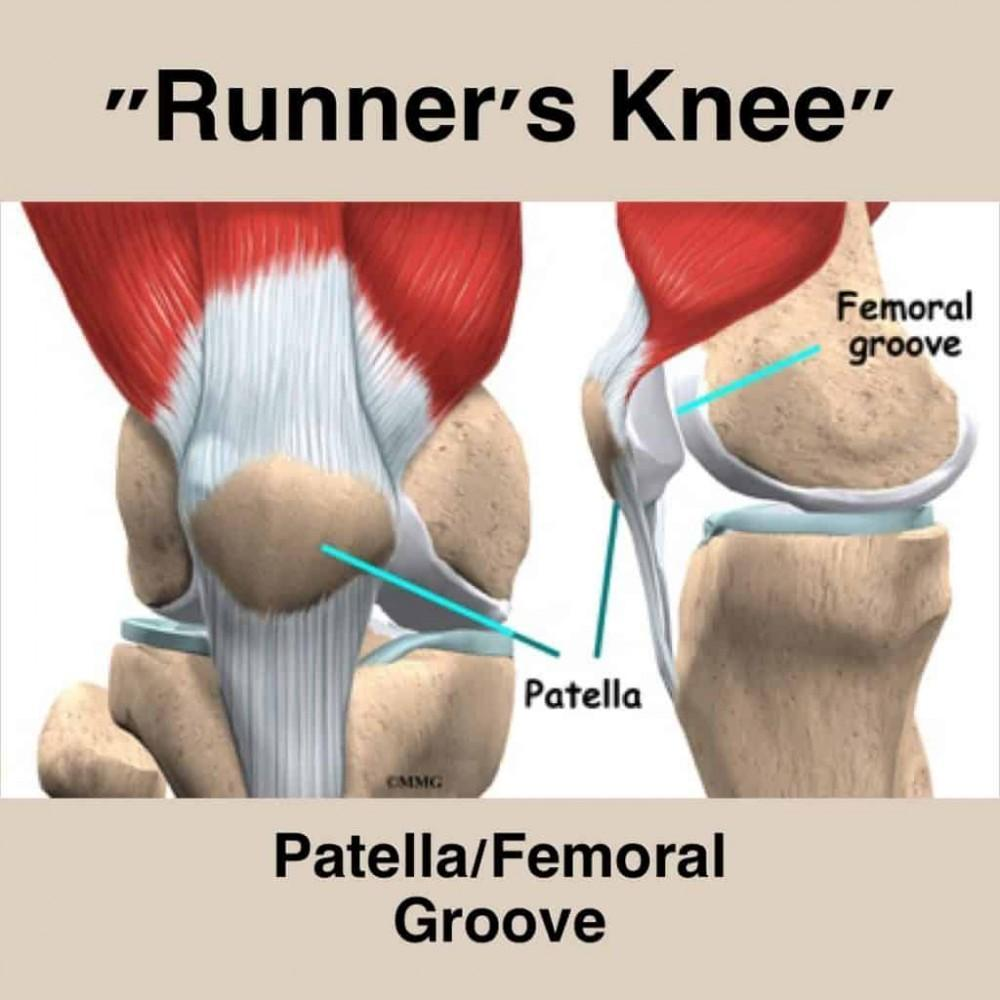
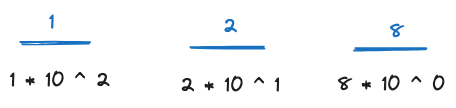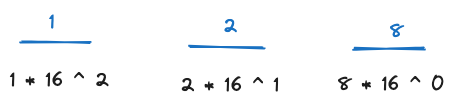since increasing my weekly milelage from 10 to 16 i started noticing mild pain on the medial sides of both of my knee caps (my right more so than my left). i also added superfeet arch insoles into my shoes at around the same time, so that may have also affected my running mechanics.
from what i’ve been able to research, the most likely culprit is patellafemoral syndrome aka runners knee given the proximity of the pain to the knee cap. it’s on the medial side just underneath the knee cap. this hasn’t really seriously affected my daily mobility or even my running since it’s very mild, but it’s something i want to make sure i nip in the bud before it develops
here’s a table of common causes and which ones i believe apply to me
cause
applies?
kneecap misalignment
don’t know
overuse
most likely. 10 -> 16 is a 60% increase! recommended is closer to 10 – 15%
injury or trauma
no
week thigh muscles
possible – i haven’t incorporated quad strengthening into my routine yet
tight hamstrings
unlikely, esp. because i stretch these during yoga often
tight achilles tendons
maybe, i don’t stretch my achilles
poor foot support
could be affected by my new arch “supports” that may be throwing off my normal gait
feet rolling in
maybe? most of the roads and sidewalks i run on have camber/slope. when i run on the road, i run on the left so there’s a leftward slope which i’m sure affects my foot roll motion
of this set of causes, the top ones are likely
overuse
weak thigh muscles. quadriceps in particular play a huge role in knee cap stabilization and when the knee cap isn’t stable it’s more likely to result in inflammation when it’s not tracking smoothly
tight achilles tendons. tight achilles leads to more of a forefoot strike during walking, and that in turns causes the quads to remain tense and pull on the knee cap
so there’s a interesting property between the XOR operation and mod 2
turns out, the xor (^) of any sequence of bits is equal to the sum of those bits modulo 2
for example
1 ^ 0 ^ 1 ^ 1 is the same as (1 + 0 + 1 + 1) % 2
if you take this step by step, the xor side:
1 ^ 0 = 1
1 ^ 0 = 1
1 ^ 1 = 0
0 ^ 1 = 1 (answer)
the modulo side:
1 + 0 + 1 + 1 = 3
3 % 2 = 1
why?
lets look at the truth table for XORs using two bits
left bit
right bit
xor result
0
0
0
0
1
1
1
0
1
1
1
0
xor table
XOR is an exclusive OR, so it will only be 1 if there’s ONLY ONE bit that’s on. if there’s two bits or no bits, the result is 0. what other operation of two operands where the result is 0 given 0 and 0 and 1 and 1? modulo 2!
this equivalence exists because when we’re dealing with two bits, their sum is 2. 2 mod 2 is 0. when both bits are 0, the sum is 0 and 0 mod 2 is 0. when only one of them (and odd number) is on, we always get a sum of 1 and 1 mod 2 is 1
even though we’re only looking at two bits, this actually generalizes to any sequence of bits because it turns out that XORing any sequence of bits results in 0 when there is an even number of 1 bits and 1 when there is an odd number of 1 bits (or none)
ever wondered what it means for a runner to be a “middle distance” or “long distance” runner? in the running / racing world there’s three main categories of distance events that differ by distance ranges
short or sprint distance
these are traditional 100 meter (100m), 200m, 400m, and the 4x100m and 4x400m relays. these are pretty much purely anaerobic events. anything beyond 400m is in the middle distance category where the running starts to demand both high aerobic and anaerobic work
medium distance
common track distances are the 800m, 1500m, milers (1609m) , 3000m and the steeple chase variations involving obstacles and water jumps. anything beyond 3000m is going to be long distance
long distance
this is where my current comfort level is with running, although i do most of my higher intensity work in the short distances. common races in this range are the 5000m or 5k (though some people also consider the 5k a medium distance event), 10k, half marathon (21k), marathon (42k), and beyond (ultra marathons) like a 50k (31 miles). pretty much most road racing and cross country running fall into long distance category.
the longest official race i’ve run so far is a super popular local 15k (https://www.boilermaker.com/). i’ve been running this race in the last 3 years. my impression is that the 15k is not a common race distance (compared to the 10k) because when i share this with people they always express surprise that such a distance is even a thing. my goal next year is to run a half marathon, so hopefully that will be my new long race record!
boilermaker fun fact: the boilermaker actually draws a good number of elite international runners – this past year the winner was john korir of kenya who’s one of the current top 10 marathon record holders!
boilermaker fun fact 2: not sure if this is verified, by i learned this through my wife. the event takes place in july, which seems odd because it’s a distance event that’s smack in the height of summer heat. but this is a couple of months before the marathon majors in the U.S (nyc, boston, chicago…) that run between september – november, so this off season schedule suits international runners that are training for the majors. i think this sort of makes sense because if they stuck the race in november, there’s probably going to be a non-existent elite pool…
anyway, here’s an easy / quick way to remember these ranges
short distance – up to a single lap on a standard outdoor track (400m)
medium distance – up to a 3k / two miles / 8 laps on a standard outdoor track
i’m currently working on running a consistent weekly mileage of 16 miles this year and hopefully making my way up to 20-25 by the beginning of next year.
so far … it’s been going mostly good. a couple of weeks ago following a 5k race (i hit a pr of 23:57 at a 7:43 mile pace!) i started experiencing some very mild symptoms of runners knee / patella-femoral syndrome (more so on my right knee, towards the medial underside of the patella) but it seems to be subsiding / not getting worse over time. i’ve been trying to loosen up my quads a bit with rollers to see if that helps but i’ll keep an eye on it
my current training schedule is:
sunday
long run (8 miles)
monday
recovery / easy run (2 miles)
tuesday
recovery / strength training (lower body) (3 miles)
wednesday
easy run combined with a workout like strides or tempo
thursday
recovery / strength training (upper body) (3 miles)
friday
easy run combined with a workout like stride or tempo
saturday
rest / recovery. no strength training to prepare legs for long run the following day
this schedule is basically identical to the boilermaker 15k training program that i’ve been following for the last 3 years (very inconsistently). in my first two boilermakers i ran with my wife and we did about an avg 12min pace and finished in just under two hours. this year in july i ran by myself and finished in 1:28 at a 9:31 mile pace.
the key thing about this training schedule is that it follows a mostly low intensity, 80/20 philosophy where at least 80% of the runs are easy runs and at most 20% is high intensity. with 16 miles per week, 20% is about 3 miles and that’s how much time i try to spend in higher intensity running distributed between tuesday and thursday. outside of that, i try (but not always successfully…) to stick to an easy pace of 10-11min mile.
there’s a couple of tweaks i’d like to start making to my running moving forward to hopefully reduce any risk of injury and improve my overall enjoyment of running
adopt RPE (rate of perceived exertion) as primary measure during my runs instead of glancing at my watch first to gauge effort based on pace or heart rate. i run on hills often and sometimes focusing on pace causes me to go much faster than i should for easy days
pick a couple of specific and recurring workouts for my run workout days on tuesday and thursday. right now it’s a bit make up as i go and i’d like to just remove that decision making on the day of
hex notation shows up a lot in computing so it’s really useful to understand. it’s really hard though to learn to take your base 10 lens off because that’s what we’re so accustom to!
in base 10 position notation, each place represents up to 10 digits (0-9). this is really handy because when we go beyond 9, we can shift over and use a new position to denote 9 + 1. so the value of each position in a base 10 integer is essentially the radix (10) raised to the power of the position index which starts at 0.
for example, the digit symbol 8 below represents the value 8 because every digit is below 10. once you most leftward to a new position, each digit actually represents 10^1 all the way to the leftmost position 10^n.
the same set of digits for a base 16 system ends up looking the same, but the actual value is different. below, 128 in base 16 is 296. from right to left, 8 + 32 + 256 = 296. this is because rather than representing 10 symbols in each place, hex holds 16 symbols
in base 10, each place holds one of 0,1,2,3,4,5,6,7,8,9. in base 16, each place holds one of 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F where A = 10 (base 10), B = 11, C = 12, D = 13, E = 14, F = 15. so A in base 16 is equivalent to 10 in base 10. when looking at this for the first time, it looks wild because you’re so accustomed to equating the symbols “10” with the value “10” (both in base 10), so switching bases really requires you to decouple the numerical symbolic representation (may or may not be base 10) from the value (which you still want to think about and write in terms of base 10).
one of the handiest things about hex and why it’s commonly used in computing is its relationship with binary or base 2 notation. machines encode all information in binary format. compared to decimal and hexadecimal, binary notation only holds 2 values in each positional index (0 and 1). the interesting relationship, though, between binary and hexadecimal is that 16 is actually 2 raised to the 4th power. put another way, we can represent any single hexadecimal value with four binary values and vice versa. this makes converting values between the two bases much easier than converting between binary and base 10. i highly recommend checking out this khan academy video to gain a intuition behind the why
thanks to this relationship, we can use hex as a far more compact literal representation of binary values. while binary is the most efficient for computers, writing in hex makes it far easier to write and read for humans. for example, the bits 1111 can be represented with just F since they both represent the value of 15 (decimal). four bits can represent up to 15 values. what else represents 15 values? a single hexadecimal digit! and since hex is a power of 2, we can expand this beyond just four bits – we can pretty much use hex to quickly convert really any sequence of bits in most computing architectures whether they’re 32bit (8 groups of 4 bits) or 64bit
a common task i do is open bash in a container to inspect the file system….
but what happens when there is no shell at all in the image?
for example
FROM scratch
WORKDIR src
COPY README.md .
and if i run docker build . -t minimal-image to build the image, how would i confirm the contents were indeed copied over?
if i run docker run minimal-image:latest bash, i get
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: "bash": executable file not found in $PATH: unknown.
this makes sense because the scratch image doesn’t actually contain anything. it’s not shipped with a bash interpreter.
so what to do…
the workaround is to use the docker export command. this requires a container, so first build the container
and then we can finally export this to a .tar file
docker export minimal-container -o out.tar
now lets unzip/decompress the tar into a directory called tmp. if i don’t specify a destination directory, the contents will get unzipped directly into my current directory, which includes my host files! don’t want that 🙂
mkdir tmp && tar -xzf out.tar -C tmp
this gives me, with ls tmp
dev
etc
proc
src
sys
now before i had my WORKDIR image instruction to set the working directory to src right before my COPY instruction, and that is indeed where i find the file i copied.
anyway that’s how you inspect contents of an image without a shell!
bind mounts are what i’m accustomed to using for local docker dev. they’re the typical go to for being able to use host-native dev tooling to edit source code and ensuring that those changes are immediately reflected in the container environment. they work fine, for the most part.
my biggest issue with them has always been the speed on mac. every company i’ve worked at provisions mac’s for dev machines and the biggest reason for the slowness is because on a mac, docker is actually running in a linux VM. afaik there is no native mac container technology – they’re built for linux. so docker makes this work by running a hypervisor using apples virtualization framework. virtualization is cool but it’s expensive.
when docker desktop starts up, it mounts paths like /Users into the virtual machine and makes that available to processes running inside the container. this is what allows source directories in the mac host machine to be bind-mounted. unfortunately, every i/o operation incurs an extra cost in mapping a read or write operation in the virtual machines virtual file system to a read or write on the actual host file system.
i don’t think there’s much you can do about this cost – it’s always going to be an extra level of indirection so it’s not going to ever match native, no-container i/o speeds. but there are some alternatives that i’m eager to try out in the future
dev containers is basically taking containerization to the extreme – what if your entire workflow / tooling was inside a container?!
docker released https://docs.docker.com/desktop/synchronized-file-sharing/ , this tackles this problem by asking the question “what if we can copy/sync file changes really fast into the container?” instead of forcing the vm to reach across file system boundaries
lately i’ve been going through crafting interpreters by bob nystrom using racket and its got me thinking a lot about code gen in java vs lisps. the book uses java and there’s some use of it to template out common patterns. it’s about as awkward as i expected it to look. but i’m not writing to pick on java – mostly to appreciate the special niche that lisp continues to occupy
in java, if you want to generate a set of classes, you have to write a class that can output strings that will ultimately represent a valid java program. at runtime, you may have a method called generateObject that accepts some arguments and outputs the blueprint of a class. the output will be strings or even files but they are not being generated and compiled at the same time. another stage of compilation on this outputted source will need to be performed.
i don’t mean to pick on java. this separation of code generation and compilation in meta-programming (meta because we’re using a program to produce more source code) is common in most statically typed languages.
dynamically typed languages and interpreted languages such as ruby and python support program generation and execution of the generated code both at runtime.
for example, ruby supports defining methods dynamically at runtime that becomes available to the rest of the system via define_method and it can even evaluate arbitrary ruby code using functions like class_eval. these definitions are parsed and executed at runtime.
however, any sufficiently complex program can only be represented as strings and thus the only way to manipulate them is as plain strings.
in both situations, whether dynamic or static, languages have
a representation of a program in a particular language that conforms to a special grammar, usually EBNF
a set of primitive data structures that can be manipulated at program runtime
and the actual program representation does not conform to the same structures as its data structures. in other words, the language does not allow the program itself to be treated as a data structure – because the literal representation of the program itself (that a programmer sees) is not a data structure but rather just text strings.
take ruby as an example
class Animal
def initialize(name, sound)
@name = name
@sound = sound
end
def make_sound
puts "#{@name} says #{@sound}!"
end
end
# Creating an instance of the Animal class
cat = Animal.new("Cat", "Meow")
# Calling the make_sound method
cat.make_sound
that’s a representation of a ruby program – in no way does that resemble any of the data structures in ruby such as arrays or dictionaries.
program source representations as part of a interpretation or compilation process do eventually undergo transformations (i.e class_eval) that turn plain source text into data structures that can be manipulated. for example, the lexing and parsing phases of compilers product syntax tree data structures that can in fact be expressed with the same primitive structures supported by the language itself.
the keyword here is “eventually”. the program as it is represented before any compilation or parsing occurs is not a data structure and cannot be manipulated as such. this is as true for ruby as it is for java
lisp
the one exception to this is lisp. the fancy academic word used to describe this unique position held by lisp regarding the discrepancy between the languages external representation and its data structures is homoiconicity.
lisp is homoiconic because lisp programs manipulate s-expressions and are also written in s-expressions.
here’s a simple demonstration using a dialect of lisp (racket scheme) where we define an original program (as a list) and then we transform the program literally before eval’ing it.
since our original-program is just a list, it can be manipulated like any other list using functions like car. notice here how there’s no distinction between a manipulated program and the surrounding program representation. it’s all just lists. that is code as data.
this power extends not just to arbitrary program eval and manipulation – lisp also lets you extend its syntax in new ways to support custom language features that are not built into the language. these are known as macros. again, since the language is made up of s-expressions, any new formulation or semantic of the language can likewise be expressed in s-expressions and can be expanded and eval’d as if they were any other data structure during runtime, without having to drop into a “compilation” stage that converts something more primitive like strings into an AST
the whole language is an AST!
i’ve long wondered what the yinyang symbol of lisp represented and it’s actually from structures and interpretations from MIT. the yin yang represents eval and apply in the metacircular evaluator from the textbook. the metacircular evaluator is basically a lisp interpreter written in lisp – it is lisp evaluating itself through the use of both eval and apply.
the expression problem states that it may be easy to extend data types in a program without modifying existing code and it may be easy to extend behavior in a program without modifying existing code, but not both. this limit, as far as i know, is a limit imposed by the design of the underlying programming language. i really don’t like the name of this problem because the issue isn’t just a matter of expression, it’s also one of modification. so maybe we should call it the expression-modification problem…
object oriented languages or languages that are oriented towards concepts like colocating data and behavior under class-like constructs tend to be better at allowing you to add new types to a system (provided they follow the same behavior contracts) without having to open up and modifying existing type. for example, if you have a set of data types representing cars and they’re all supposed to understand the method / message “accelerate”, you can easily add new cars with different acceleration behavior. however, the moment you need to add a new behavior that affects all existing cars (lets say a new method named “recall”), every single class will need to be opened and modified.
functional languages or languages that are oriented towards separating data and behavior tend to be better at allowing you to add new behavior to a system without having to modify existing code. using the same example as above, if you needed to add a new function, you just need to add a new function that handles all the various car types. however, if you need to add a new data type like a new car, now you need to open all of the existing functions to handle the new type.
from a practical standpoint, what this means is that choice of language matters depending on the problem at hand because the language orientation, if one exists, can either work with or against the programs natural architecture. for example, if you’re dealing with a problem with a handful of fixed data types and most of the growth is in domain specific behavior, a function oriented design may be more compatible.
for example, lets say you have a computing problem dealing with some fixed set of accounting related concepts that are stable and don’t change overtime. but stakeholders frequently need to perform different types of reports on these various types and these reports frequently evolve and change. with a more strict OO approach, the reporting behavior may be co-located with the domain objects but this means having to open up each one every time a new reporting behavior is added (OO languages make cross-cutting behavior sharing easier with inheritance, so, lets assume the worst case and that the concrete behavior of each new report needs to be specific to each type).
nowadays we have many “multi-paradigm” languages that allow programmers to choose the more suitable style or change it if it no longer fits, but i don’t think this solves the expression problem in so much as it forces the user to pick the side of the problem they want to have. lots of problem domains also grow on both axis (data types AND behavior) and it’s not always clear which one you’re dealing with, so the problem cannot always be avoided with more planning.
from my experience, it’s easier to start with a function oriented program for most problems that are ill-specified because you can easily and quickly represent types using lightweight data types and start doing useful things with them. with object oriented approaches, particularly with statically typed ones like java, it often feels like there’s a much higher startup cost to expressing the program because before you can even get to defining any useful behavior, you have to define some set of classes (which are far more rigid and hard to change than more primitive data structures).
A common task I use for react is rendering large datasets in the UI. For example, a large list of movies or books. Here’s a simple component that renders a list of movies.
As long as you’re using a unique `key` attribute in this case, renders are pretty fast. In the example above, only simple list items are being rendered for each movie. It’s a small set of elements and there’s no complex state involved.
But what if…
The individual movie items are a lot more expensive to render and contain a lot of state
The state cannot be localized to the smaller child components and needs to live at the root level (because it’s shared with other components)
Here’s an example where we have a parent level state that maintains rating data and passes that down to render both the movie list and a sibling recommendations component.
In this case, if setMovieRatings gets called in any of the children ExpensiveMovieItem components, the parent state will update and all of its children will re-render (even if the props for the majority of components in the list stays the same). One common misunderstanding I had for a long time is that when props stay the same, a component does not re-render. In reality, any time a parent UI component state changes as a result of setState, all of its descendants re-render.
If this is a large list (1000+) items, this re-render can create noticeable lag. In this case, if the re-render takes 200ms, it’ll take 200ms between when a rating for a movie is updated to when it’s actually reflected in the UI. Since React does not care to skip re-renders automatically based on props, it’s up to you to tell it when to skip a full re-render for a component.
React.memo
React.memo is a function that accepts a component (and an optional prop comparison function) and returns another component. This new component has special memoization behavior that skips re-render based on either the built-in or user provided prop check.
Going back to the original example, here’s how you turn a normal expensive component into a memoized one:
Now if you update the parent state, only the children with changed props will render. This technique will work out of the box if all of your props are non-object primitives (strings, numbers), but you’ll have to be more careful if you have objects because the default comparison method is using Object.is, and it’s pretty common for the identity of objects to change across re-renders in React even if the literal values are the same. For example, if you’re re-creating functions that are being passed in as props then you’ll cause a re-render. Or if you’re doing object cloning in setState which creates new objects with the same values but different identities. You can get around these issues by either simplifying the prop params or providing a custom property checker.
i’ve had a lot of JWT related discussions at work lately and today I wondered how big is too big for a JWT to fit through an HTTP header. The HTTP spec doesn’t really impose a limit but most servers do set a limit that range between 8K – 16K bytes.
I figured I can whip up a quick jwt generator to get a rough sense of how big JWT’s can get!
for simplicity I made the key value pairs small strings (these will vary in real life of course) and defined a byte limit of 8K. Also to save battery I increased the key counts exponentially 😀
ok here’s the script. can you guess what the key limit is using back of napkin calc?
chrome is planning on phasing out support for third party cookies in 2024.
Third-party cookies, also known as cross-site cookies, are cookies set by a website other than the one you are currently on. For example, cnn.com might have a Facebook like button on their site. The like button will set a cookie that can be read by Facebook.
these cookies are a big deal for big tech because they’re the primary enabler of web tracking and advertising. if you work for a tech company that relies on digital ads, chances are they depend on third party cookies for those ads to follow you around the web.
cookie basics
when a browser issues a request to example.com, example.com can set a cookie on the browser under the domain example.com by responding to the request with a set-cookie response header.
once the cookie is saved, if the browser makes additional requests to example.com again in the future, the cookie under the matching domain will be forwarded back to the server.
because HTTP is a stateless protocol, it’s this cookie behavior that allows websites to “remember” its clients.
now, whether a cookie is first party or third party depends on the domain you’re currently on. if the cookie domain is the same as the current domain you’re on (in your browsers address bar), this is a first party cookie. The cookie belongs to the domain. every other cookie set by other domains is third party. so whether a cookie is first party or not depends on two things:
The domain of the cookie
The current domain of the page
if i’m on example.com, all the cookies set under example.com are first party. the browser may contain other cookies, saved under other domains like yahoo.com or wikipedia.org. those are all third party!
so from a user perspective, a cookie isn’t first party in an absolute sense. if the user visits a different site under a different domain, the same cookie is no longer considered first party. so again, the site you’re currently on according to the browser determines whether a cookie is considered first party or third party.
issue with third party cookies
so remember how a website can set cookies under its own domain? well, turns out they can also indirectly set cookies under other (third party) domains! all thanks to the magic of
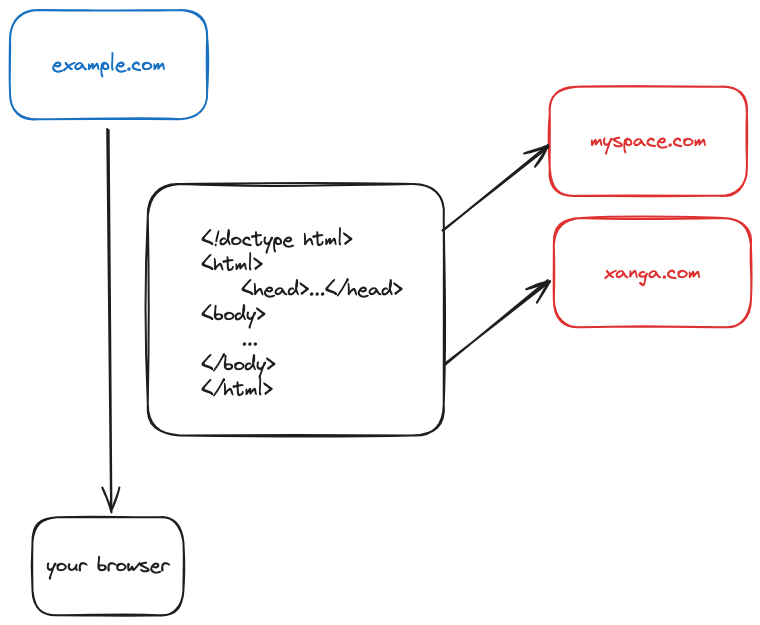
HTML documents can contain many references / links to resources on other domains. every <img src...> or <link ...> or <script src...> is basically a GET request to another server that may live under different domains than the one you’re currently on!
those third party servers i.e myspace.com and xanga.com can also set cookies under their domain. the browser doesn’t really make a distinction between a request you made directly by typing in example.com in the address bar versus ones that are fired as a result of HTML rendering.
as a result, the same website you’re visiting transmits its own cookies AND cookies from other websites. some of those websites may even be… ad networks that set cookies for purposes of analytics and tracking.
this basic auto storage and transmission behavior of cookies combined with the hyperlinking nature of web sites is at the core of how ad tech works.
if you’re an advertiser, third party cookie data allows you to learn about visitor behaviors, such as websites they frequently visits and recent purchases and target them with ads
real world scenario time
here’s a real example that i’ve researched and verified myself.
hypothetically speaking, lets say bob is researching a rice cooker on amazon.com. bob sees one he likes, but feels overwhelmed so gives up and decides to go bake cookies instead
bob then visits a site with a cookie recipe and sees an advertisement for the same rice cooker he was looking at earlier. since bobs not on an amazon-owned site but is seeing amazon related ads, this advertisement was triggered by a transmission of third-party cookie data.
the third party domain in this case is amazons advertising network. amazon has an advertising network similar to Google’s doubleclick.
here’s an example of a real cookie that’s set by the ad network when you visit amazon.com:
when a page on amazon loads, it makes additional requests to the amazon ad network. the ad network sets this very long-lived cookie (at the time of writing, that date is more than 4 years into the future) that will be used to track your behavior. for the next 4 years, this cookie data will be forwarded to any request to the amazon ad networks domain .amazon-adsystem.com.
a quick aside about ad networks
there’s three primary groups involved in an ad network
sellers that have something to sell (companies selling rice cookers on amazon.com) and want their products to be advertised as widely and cheaply as possible and
those who want to make money by showing ads (content creators, bloggers, etc). amazon calls those that want to show ads through their web content associates.
consumers / buyers / site visitors
the value of an ad network is proportional to the size of these groups. if there are no consumers or buyers, there’s nobody to sell to. if there are no content creators / youtubers, ads are limited in their reach. if there are no sellers… well, then there are probably no ads either!
back to bob
now that the third party cookie from the ad network is set, when bob visits a recipe site that’s also part of the ad network, he’s going to load a third party tracking script (also known as pixels) from .amazon-adsystem.com that receives the cookie that’s set, looks up the user by ID on the amazon servers, and serves a targeted ad based on the information the ad network has on the user identified by the cookie.
over time, these scripts loaded by sites that are affiliated with the ad network continue to track bobs behavior through the long lived cookie for as long as they’re loaded and transmit the data back to the ad network. this builds a rich representation of bob as a consumer for re-targeting purposes.
with the “end” to third party cookies, this basic mechanism is threatened. the recipe site will be restricted to only transmitted first party (its own) cookies. cookies previously set by an ad network (from a users visit to amazon.com properties) will not be transmitted behind the scenes for ad retargeting.
i should mention that most browsers do give you the option now of disabling third party cookies. yes even chrome. here’s what i see if i click into my chrome settings. as you would expect, third party cookies right now are allowed by default. i recommend turning that off.
so no more ads following me around in future?
while this looks like a positive direction for data privacy, it’s definitely not the end for ad retargeting. remember that big tech makes an ungodly amount of money from their advertising platforms and it’s not in their interest to kill their golden goose.
the current google led proposal to replace third party cookies in chrome is called the privacy sandbox initiative. a major part of this initiative is to offer users more control over how their data gets shared. i’m going to be reading more on this in the future and write about it on another post.
JSON Web Tokens (JWTs) are cryptographically signed JSON objects. The crypto signing is what provides the trust guarantees since consumers of a JWT can verify the signature using a public key. Now there’s two types of JWT’s: stateful and stateless jwt’s.
Stateless JWT’s are probably the most common JWT. All the information needed by the application about an entity is contained in the JSON (username, role, email, etc). When a stateless JWT is transmitted in a request either via cookie or header, the application base64 decodes the JWT, verifies the signature and takes some sort of action.
Stateful JWT’s contain a reference to information about an entity that is stored on the server. This reference is typically a session ID that references a session record in storage. When this JWT is transmitted to the backend, the backend performs a lookup in storage to get the actual data about the entity.
There’s almost no good reason to use stateful JWT’s because they are inferior in almost every way to regular session tokens:
Both session tokens (simple key-value string pair) and JWTs can be signed and verified by the server, but that whole process is simpler (and more battle-tested) with session key value pairs compared to JWT’s which involve an additional decoding step as well as plucking keys out of the decoded JSON for the verification step. Since most applications rely on third party JWT libraries to handle this (and they greatly vary in their implementation and security), this further increases the vulnerability of JWTs.
Encoding a simple string in JSON adds additional space usage. There’s nothing to be gained from this extra space if you’re just transmitting a single value.
Stateless JWT’s from my experience are most commonly used in service-oriented and microservice architectures where there are some collection of backend services and frontend clients. There’s typically a central authentication service that talks to a database with user information. Client requests from the frontend are authenticated with this service and receive a JWT in return. They may also need to communicate with backend services that are behind access control, so they pass along the stateless JWT as a bearer token in an HTTP header. The backend service verifies the JWT and uses the claims information to make an authz decision.
The reason why this is a popular flow is that teams are able to act on the JWT without having to perform an additional lookup about the entity at a user service. They do have to verify the JWT, but they don’t need to maintain any additional state about the user or communicate with another service. This level of trust only works because JWT’s are digitally signed by an issuing party (in this case, the auth server). If clients are just passing plain JSON requests, there’s no way for services to verify the integrity of the information (has it been tampered with?) or the source (how can i be sure it’s issued by the auth server?).
jwt as session
One common argument against the use of stateless JWT’s is when they’re used as sessions. The application basically offloads session expiry mechanism entirely to the JWT. The two strongest arguments i know of against using jwt’s as sessions are around data freshness and invalidation.
If you’re using a stateless JWT as a session, the only way to really expire a JWT is to set a new JWT on a client with an expiry in the past or change the issuing key (which invalidates all sessions). Fully client-side cookie sessions have similar limitations around invalidation. Data freshness is another related issue – when invalidation is hard, so is updating. If you need to revoke permissions, you can’t really do that without updating the JWT. But again, you can’t do that if you’re relying on the client-side state of a JWT for session management.
jwt tokens are a very popular way of transmitting claims information between systems. It’s based on a public key system so that the claims can be verified and the verifier can be confident that the claim was issued by a trusted entity.
microservice architectures will commonly use the claims to perform access control. For example, the claim may contain a users ID and their roles. This information can then be used to allow or deny access to resources.
One question that inevitably comes up when implementing JWT flows is:
How can I be sure that this JWT isn’t fake? How do I know it’s not tampered with??
if you don’t verify the signature, you really can’t be sure. JWT tokens contain a “signature” which is the output of a cryptographic hashing algorithm such as RS256. The issuer of the token will hash the header and payload of the JWT using a one way hash. This hashed output is then encrypted using a secret and then the final output gets stored inside the token. So what gets stored is an encrypted signature. If anything about the contents of the JWT changes, the signature will change.
on the receiving side, the only way to trust the token is to verify the signature. First, the signature in the claim needs to be decrypted using a public key (this is usually made available by the issuer). If you can successfully decrypt this value then you can be confident that the token was issued by the trusted party. However, at this point you haven’t verified if the contents have been tampered with / changed.
to verify that the integrity of the actual payload, you need to perform the same hash on the header and payload and compared the hashed output to the claim signature. If they match, you now have confidence that the claims were not tampered with! So there’s two levels of verification that happen. The first is the successful decryption of the claim. If decryption fails, the claim must not have been issued by the trusted party. For example, if I generated a JWT using some random secret key, it can only be decrypted by a specific public key. If I don’t share this public key with another party, they cannot trust me. So if a service is unable to decrypt using the public key it has, it cannot establish trust.
by the same token (hehe), if the verification of hashes fail, it’s possible that the token was issued by a trusted party but the contents of the JWT changed or does not match what was used to generate the original signature. This is a sign of tampering – either by another party or even by accident by the JWT consuming service (perhaps there’s a bug in the signature verification code).
reflected XSS attacks are a common way of tricking a users browser agent into executing malicious code. I’ll share onedefinition I found from mozilla and unpack the key terms / concepts.
When a user is tricked into clicking a malicious link, submitting a specially crafted form, or browsing to a malicious site, the injected code travels to the vulnerable website. The Web server reflects the injected script back to the user’s browser, such as in an error message, search result, or any other response that includes data sent to the server as part of the request. The browser executes the code because it assumes the response is from a “trusted” server which the user has already interacted with.
there’s a few key phrases here that are important to understanding XSS:
malicious link – this is the link sent by the attack to a user of a web service. Lets assume you’re the user and the service is my-bank.com. This link may look like “my-bank.com?alert=<script>… malicious code …</script>” which contains code that the attacker wants to execute on your browser.
malicious site – this is a site owned by the attacker. A malicious site doesn’t need to exist for an attack to happen, but it’s one place an attacker can get you to submit details that they can use to construct a scripted attack. For example, lets say they need your email address to perform an attack. The site might have a fake form that collects your email address and then redirects you to “my-bank.com” with an embedded URL script.
vulnerable website – this is the site that is vulnerable to XSS attacks. In general, that includes any site that doesn’t escape / sanitize inputs from the client. The problem with this is that it can lead to the browser agent executing user provided (via an attacker) javascript.
web server – this is the bank services backend service
“trusted” server – this is the bank server that returned the HTML containing malicious code that the users browser executed. Trusted is in quotes here because the server is returning javascript that it did not intend to. So it can’t really be trusted.
XSS attacks take advantage of:
A web service that liberally accepts user provided inputs (an attacker can replace a safe input with client code) and renders that input without sanitization (permits arbitrary code execution via injected script tags)
An established trust between the user agent and the web service. Any malicious code may execute in the context of an established session between the user and the service. For example, the user may be logged in and therefore all requests originating from the page (which will contain auth related cookies like session cookies) are trusted by the backend.
An unsuspecting user that blindly clicks a link (perhaps emailed to them) or fills out a form on a malicious website
err how is this different from stored XSS?
the only difference between reflected XSS and stored XSS is that with stored XSS, the malicious code is actually stored on the vulnerable web services servers. For example, lets say twitter is the vulnerable website and you’re a twitter user. Now lets assume you’re following someone who’s an attacker and they submit a tweet containing malicious code that they know will be executed by browser agents when it gets rendered, say, in the newsfeed of followers.
so here’s how it goes down – they submit the tweet containing script code. That tweet gets stored on the twitter servers (this is where the word “stored” comes from). That tweet will be rendered in users news feeds and when it does, the contents of the tweet gets executed as javascript. Boom, that’s the XSS attack. Just like reflected XSS, this can be prevented by ensuring that user input (in this case, tweets) is sanitized.
eric brewer presented CAP at a distributed computing conference in 2000 to designers of distributed systems, most of whom were familiar with relational databases and their consistency guarantees. His intention was to start the conversation about trade-offs in the system design space that need to be made between consistency and availability for early cloud-based storage systems that needed to be highly available. His main argument was that systems that for cloud storage systems to be highly available, some level of consistency needed to be sacrificed.
most developers like myself are using distributed systems – not designing them. more importantly, i find that i’m often required to think about app data usage patterns and how their storage system supports those usage patterns at levels far more granular than what CAP offers. as a distributed systems user, CAP can basically be reduced to “there’s a trade-off between availability and consistency”. that’s a concept that i find much easier to digest on its own
more useful questions / concepts than CAP to grapple with are…
is replication synchronous or asynchronous? Is this adjustable?
In the event of node or network failures, what is the data recovery process like? what writes get rolled back?
is there support for transactions? what level of isolation is supported (are dirty reads possible?)
can I read my own writes?
how do I scale reads and writes as my system grows? what does the process of adding additional nodes to the system look like?
how are concurrency conflicts handled / when there is contention over shared data?
one misconception of mongos read concern: majority is that it guarantees read-your-write consistency by reading from a majority of nodes. this is a common misunderstanding because it’s counterpart write concern: majority requires acks from the majority of nodes.
… but that’s not at all what read concern does!
reads always get submitted to a single node using a server selection process that takes into account your read preference (primary, primaryPreferred, secondary, etc).
if you have a primary read preference, a read will always go to the primary.
if you have a secondary read preference, a read will get submitted to a single secondary. if you have two replicas, a read goes to one of them
when the read concern (not the same as read preference, great naming mongodb) is set to majority, that’s basically saying “only return data for this query that has been committed / successfully written to the majority of nodes”.
this does not mean that you’re always reading the latest write
to understand this, you need to understand mongo’s notion of a “majority commit”.
the majority commit value for any write is determined by the primary during the standard replication process. when data gets replicated to a secondary node, it’ll check with the primary whether to update it’s “majority commit” snapshot of the data. If that value has not been majority committed, the majority commit snapshot will maintain its previous majority committed value.
that’s why it’s still possible to read stale values with read: majority. The majority commit snapshot on any given node is only updated for a particular value when it is actually successfully replicated from the primary to the majority of its secondary nodes. so the node you’re reading from may not have the majority-committed version of the data you literally just wrote. it’ll give you the previous majority committed value, instead of the latest value that perhaps has not yet propagated to the majority of nodes.
errr so what’s the point even MONGO
what it does mean is that you can trust that the data you’re reading has a high level of durability because in the event of a failure the value you’re reading is unlikely to be rolled back since it’s been majority committed.
read your own writes for real
reading your own writes is a special case of causal consistency and while having a majority read concern is not sufficient, it is a necessary component of setting up read your own write consistency in mongo.
to achieve reading your own writes, you need to ensure the following mAgiCaL settings:
why do you need to set specific read and write concerns even though causal consistency is enabled? I’m not sure, but it’s an extremely confusing and misleading API
theoretically/formally speaking… causal consistency includes read your own writes consistency, but in MongoDB enabling causal consistency is not sufficient for reading your own writes!
if you do have these settings on, MongoDB will track operations with a global logical clock and your reads will block until it’s able to read the most recent majority committed write from the same session.
without causal consistency enabled, a write may go to a majority of nodes but the read may still would up returning non-majority-committed data from a node that does not have the write that just happened in the same session. The causal consistency session is what causes reads to block if it attempts to read a stale write.
wow this sounds painful what are my other options
situations involving multi-document operations are most likely going to bring up requirements around read/write consistency. the best way to skip all that is to use mongo / nosql as it was designed and focus on single document, atomic operations that do not require you to interleave read and writes. this means modeling your data in a de-normalized way and not treat mongo too much like a relational db. it’s actually what they recommend too!
i’ve been thinking about saml and oauth a lot lately due to work. i’m putting down some of my thoughts here on how i believe they differ in purpose.
lets say there’s COOL WEB APP with a typical authentication using email and password. these creds get transmitted in a HTTP request and server backend verifies the credentials and grants access to user (hopefully user credentials are stored in an encrypted form…).
but there are many situations in which you may not want to be the one in charge of creds. maybe you’re scared. or maybe you want potential users to log in using their existing account with a different service (say, Google or Facebook) for convenience. or both.
if the user authenticates with a third party service (that you trust), you are basically delegating identity verification to a separate service. this is sort of the point of both SAML and OAuth at a high level, but they’re designed for different problems.
oauth
implementing OAuth in the web app lets users of that app access the service through a trusted third party that does the auth. The user goes through a login flow with the third party and eventually the third party grants a token that your app can use to retrieve user information (such as email) that can be used to grant access to the COOL WEB APP.
as a user, i might access multiple services with different oauth flows. if i use service A, i might oauth with my google login. if i use service B, i might oauth with my facebook login. but what if i want to be auth’d into both service A and service B using single auth step AKA single sign on. i’m lazy and i don’t want to use different oauth flows for each service. or maybe i’m a big corp and i want to centralize IT auth flows
OAuth, however, is not designed for single sign on scenarios (please correct me if i’m wrong!)
saml
that’s what SAML addresses! Implementing SAML for a web app is similar to OAuth in that identity is being delegated the auth to a third party, but in this case that third party is a specific entity known as an “Identity Provider” (IDP).
the responsibility of an identity provider is to grant a user access to multiple cool web apps, not just the one COOL WEB APP. the way this works is that each of those web apps have a trust relationship with the identity provider. so first trust is established with the IDP and that trust and then used to gain access to the related services. that’s basically single sign on in a nutshell.
the user signs into a single service (the identity provider) and that service has a trust relationship with N services. The user can then log into N services (one of which is yours) all mediated through SAML. this is why i believe someone came up with the fancy $100 dollar phrase “federated identity”
in data modeling discussions I often hear the phrase “non-relational data”. it’s usually someone making a case for why data should be in a NoSQL store and live denormalized. the argument is usually that the data itself is somehow inherently non-relational and so it should be put in a non-relational database.
in reality, most complex data have relationships and every conversation about storage systems is fundamentally about how to most effectively store and fetch that data. it’s a lower level implementation detail. so depending on the use cases and constraints, that data may be stored in a relational database or a non-relational database, but the data itself is not inherently “non-relational”.
for instance, lets say you’re storing user analytics data and each user has many devices. there’s a one to many between a user and their devices, but if the devices list is append-only and you’ll never have to mutate any individual device, maybe there’s no need to have a normalized representation between users and devices that requires you to pay processing time for reads which require JOINs.
still, I don’t think that makes the data non-relational – there’s a one to many relationship. what it does mean that there’s a processing performance trade-off if it’s stored in a normalized form (which you can usually do in a non-relational database nowadays).
two phase locking is an old method of ensuring serializable transactions using locks.
a common issue with non-serializable isolation (which is typically what most rdmses support…) in the fact of concurrent writes is the lost update problem.
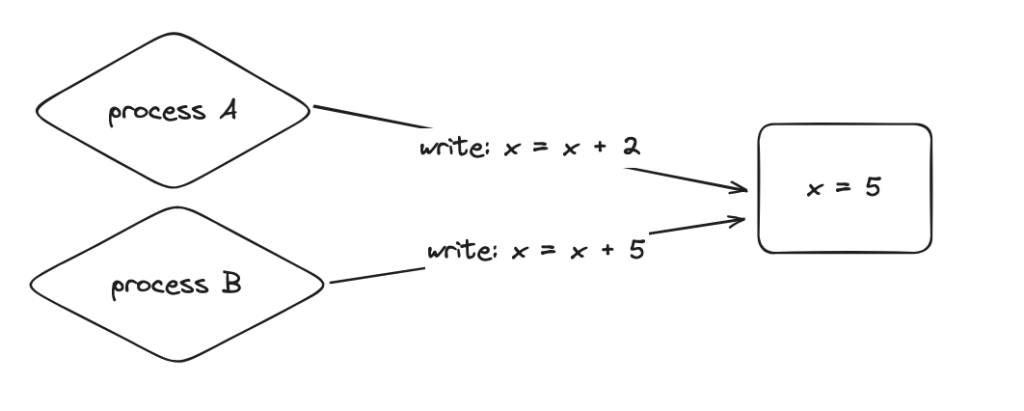
here’s an example of a lost update, lets assume:
a a record in a database with column x that has a value of 5
there are two independent processes that will perform a read-modify-write on that record
the two processes read the current value at the same time. assuming readers don’t block readers, they’ll read the same value
process A will attempt to read the current value of 5 and increment it by 2
process B will attempt to read the current value of 5 and increment it by 5
process A writes first and the new value of x is 7
process B writes last and the new value of x is 10. The update from process A is considered lost / as if it never happened!
some databases will detect a write conflict like this and raise an error and others may just proceed without a hiccup. In either case, there’s a potential conflict that may need to be resolved depending on the expectations of a client. If this is a bank account, a lost update is a huge problem. If this is a view counter, maybe it’s not as big of a problem.
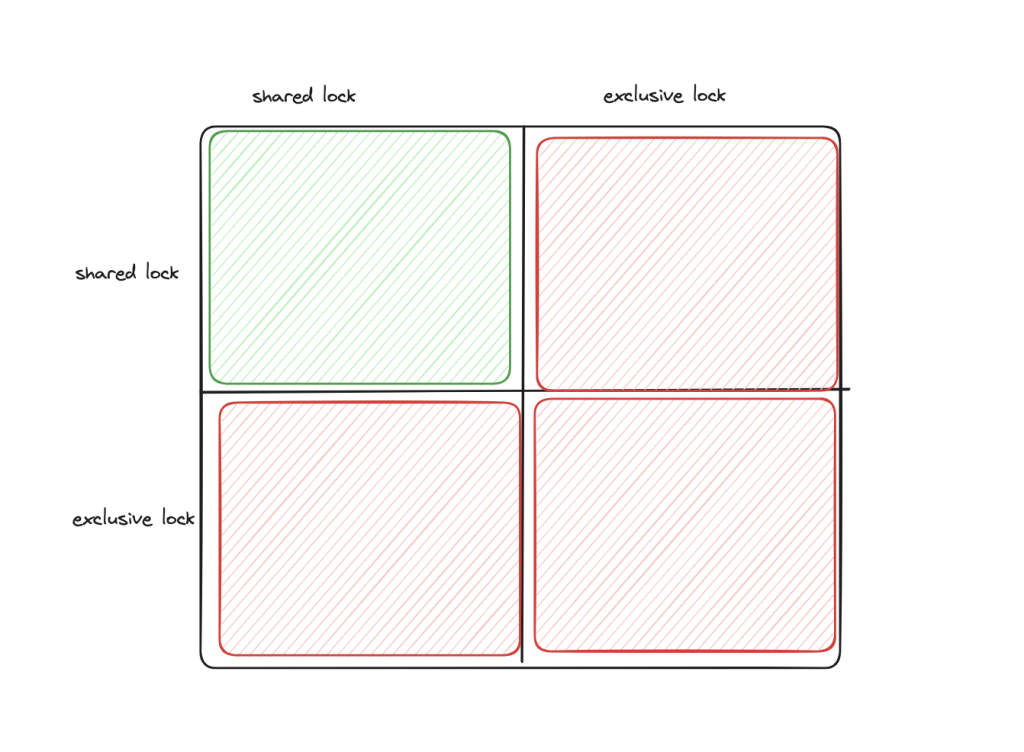
(conservative) two phase locking
there’s two types of locks in two phase locking (2PL): shared locks and exclusive locks. exclusive locks block both reads and writes. only shared locks can be shared. In snapshot isolation levels, exclusive locks from writers only block other writers – readers can still read records that are exclusively locked. with serializable, writers can block readers.
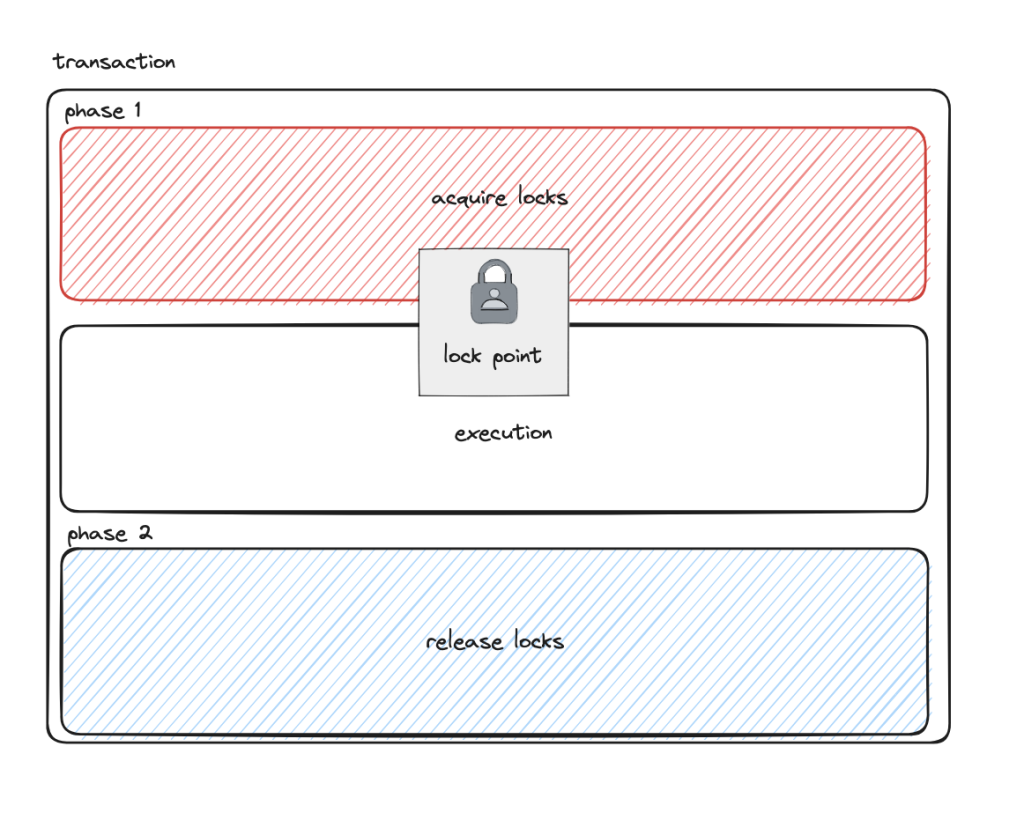
the reason 2PL is able to guarantee serializability is by splitting it locking behavior into two phases – one before actual query execution and the other after.
prior to actually executing the query, the query planner figures out what locks it needs to obtain. If a transaction only does a read, only a shared lock is acquired for that record. If, however, a transaction does a read of a record followed by a write to the same record, the shared lock is “upgraded” to an exclusive lock.
once all the locks are obtained (lock point), the locks are held until execution is complete. If you have two concurrent transactions, the first one with an exclusive lock to reach the lock point will block the other. This is what ensures serial execution.
and finally, the reason this is sometimes referred to as conservative 2PL is that it obtains all the locks upfront regardless of whether or not it needs to.