i’ve been reading oauth vulnerability reports to better understand the various attack vectors. a common one is a case where the redirect_uri is not validated as part of the initial authorization request. i found an old hackerone report about this exact scenario
here’s the report
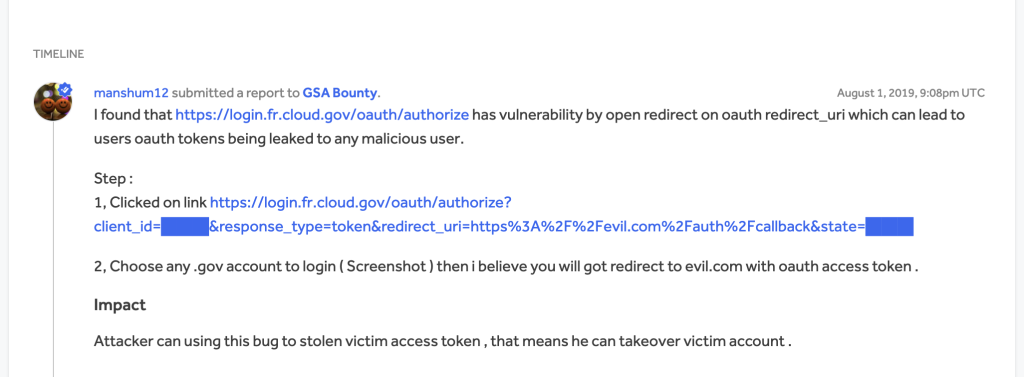
ok so login.fr.cloud.gov is clearly the authorization server. the attacker is using a registered oauth client with the provider that is configured with a different set of redirect_uris. im going to guess the attacker doesn’t actually own the client app in this case. the client_id is not a secret, so its fairly easy to get a hold of. once the attacker in this case constructs the link with their own custom redirect param, they can share it
as part of a phishing attack, an unsuspecting user can click on that link and authorize access. upon success, they will be redirected to a valid redirect url with a code parameter that can be exchanged for an access token. now that access tokens can be made against the server for user data
the reporter here is suggesting that an attacker can provide any malicious url, so that the authz code actually gets redirected to evil.com where the attacker can retrieve the code. for them to really do anything with the code, we probably have to assume that this is an implicit grant flow where the authorization step actually redirects with an access token (actually this reporter does mention access token in the report, so thats probably a safe assumption). otherwise, an attacker can’t really do much with the authz code without the oauth clients full credentials.
the simplest way to mitigate this attack is to make sure redirect uris are validated properly. nowdays it’s also not recommended to use implicit grants that do not require the oauth client to present an authz token along with protected credentials. if you have a confidential oauth app, you need to use the authorization code flow.
