A distributed cache is a remote caching system that an application uses via a network to reduce read latency. There are lots of ways an application can interact with this cache and there tends to be common access patterns or strategies – one of the most popular access pattern is called “Cache Aside” (sometimes also referred to as look-aside or lazy load) and I’ll cover both the benefits and risks of this pattern in the context of a web app.
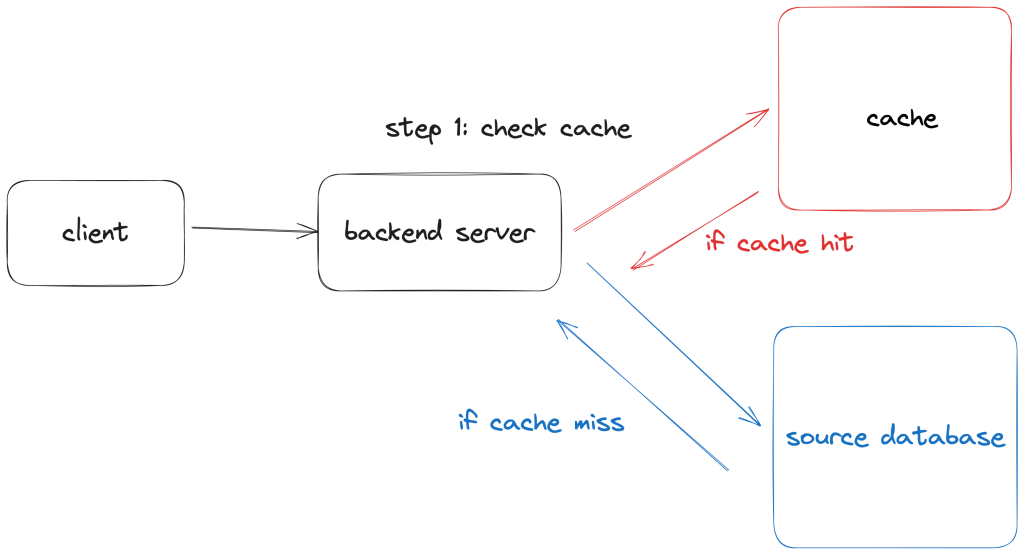
In a cache-aside, the application is able to connect to both the cache store and the source store (this is typically the primary, higher engine latency data store). If the application is a web application, the way this pattern works is:
- App receives a request for data.
- App looks up the data in the cache. If it’s in the cache (cache-hit), return it. If not (cache-miss), fetch the data from the source.
As with any caching pattern, the usefulness of a cache is influenced by how much faster it is to access the same copy of data from the cache compared to the source and the cache hit ratio (also known as the hit ratio or hit rate).
A cache hit ratio is the percentage of total requests to the application that results in a cache hit (number of cache hits / (number of cache hits + number of cache misses)). If you have a cache hit ratio of 1, that means every request resulted in a cache hit. If you have a cache hit ratio of 0, that means no requests resulted in a cache hit.
Pros and Cons
Here are some advantages or benefits to using a cache-aside pattern:
- It’s relatively straightforward to implement once you’ve identified what you want to cache. In most cases this involves adding a single new line of code to perform the lookup in the cache before executing the original source store lookup. As a maintainer of that code, it’s also easier to reason with since the caching decision is made explicit in the source code.
- You’re more likely to cache data that is going to be requested multiple times because you’re always caching by demand. The cache store is only populated whenever there is a cache-miss, so you’re more likely to cache the data you actually want cached and the storage footprint is lower.
- Since you’re caching on demand, you can start benefiting from this cache pattern immediately once it’s in place because the cache will naturally fill up overtime without requiring any sort of offline cache pre-population.
- In the event of a cache fail-over event, there’s a natural fallback already in place in your application (hitting the source database). In other words, since the application knows how to connect to both data stores, there’s a built-in redundancy which makes it more resilient to caching system failures.
Risks or things to watch out for with this pattern:
- Since we’re only caching on demand, there will always be a cache-miss for initial requests. This might be bad if the cost of a cache miss is very high (lets say it involves some heavy compute that will cause potential customers to your site to bounce). When there’s high load, you’re also susceptible to a cache stampede.
- Cache-invalidation is something you still need to reason about since this pattern has zero say / opinion on how data stays fresh once it’s stored for the first time. How long does it stay in the cache (TTL) ? What are the requirements around data freshness? If the underlying data is something that changes often (lets say it’s a list of book recommendations that gets pre-computed offline), how do you push those changes to the cache if at all? These are generally important questions to ask regardless of what caching pattern you’re using, but they’re especially critical when you’re using this particular pattern.
- It’s very easy for the cache to become load-bearing overtime. If an app cannot adequately service it’s normal levels of traffic without the cache, the cache is load bearing. This isn’t great because it means that the cache becomes a single point of failure for your business and this dependence creeps up with this particular caching pattern because it’s easy to ignore the real costs of data access once you’re serving the majority of your traffic via the cache.
On cache hit ratios
The cache hit ratio alone doesn’t say much about the usefulness of a cache.
What you’ll typically notice with this pattern is that the hit rate starts out very low (on a cold cache) and then gradually increases as more data is cached until it stabilizes. If you’ve just restarted your cache and it’s cold, having a hit rate of 0 for the first say 10 minutes doesn’t tell you much about the effectiveness of the caching pattern if eventually the hit rate rises and stabilizes at a satisfactory level.
Traffic patterns can also affect your cache – if you’re experiencing a period of low variability in queries, your hit rate is going to be high during that period which may be misleading if during normal periods of traffic you get a much wider distribution of unique requests that are likely to miss your cache.
Lastly, if your hit rate is high, it really only tells you that your cache is working but not whether it’s actually working better than the actual un-cached path. Long story short – it’s a data point, but don’t take it as gospel and look at it in context of your entire application.